
Stop Maintaining API Docs Manually: Our OpenAPI Generation Journey
How we built a system where tests generate docs, SDKs, and code examples from a single source of truth

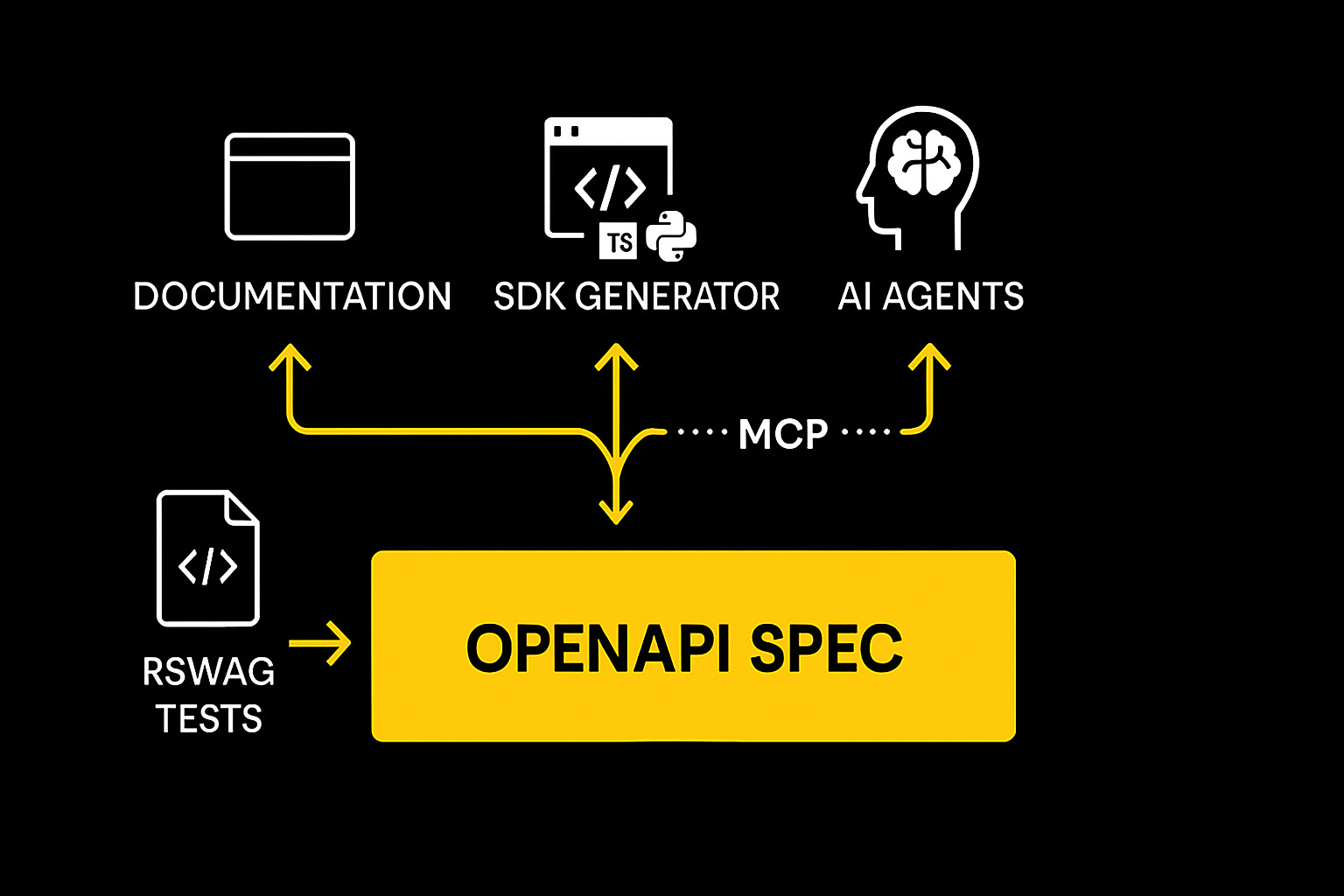
Part 1 of Building a Modern SDK System From Scratch
After building and maintaining APIs for 15 years, I've learned that the difference between good and great developer experience often comes down to documentation and SDKs. At Embed Workflow, we're building APIs that developers integrate deeply into their products, which means we can't afford to get this wrong.
Here's how we architected a system where our API tests generate everything—documentation, SDKs, and even code examples—from a single source of truth.
The Challenge: Building APIs Developers Actually Want to Use
When you're building a platform that other developers will integrate deeply into their products, the stakes are high. At Embed Workflow, we need:
Rock-solid API documentation that's always accurate
SDKs in multiple languages (TypeScript, Ruby, Python to start)
Code examples that actually work (novel concept, I know)
A system that doesn't require manual updates every time we ship
After maintaining API docs manually for many different products, I've seen the pattern: documentation drifts from reality, examples break silently, and engineers forget to make updates.
The Approach: Tests as the Source of Truth
Developer experience is non-negotiable for us. We needed a way to ensure our API docs stay in sync with our actual API, which meant keeping the documentation definitions as close to our Rails API code as possible—ideally inline with it.
1. RSwag without the UI
We decided to use rswag to generate our OpenAPI file. I've used it many times before and my previous teams all had access to the ever so popular swagger docs UI. Close your eyes and you'll see that clunky green interface.
The UI is actually great for internal use, but in the spirit of eating our own dog food, our team should be using the same docs as our customers. And that UI isn't going to cut it. Not for purely visual reasons—if that were the case, we could custom style it. I want our docs to include SDK code examples, endpoint definitions, links to guides, custom components... you get the idea. We need control so we can be creative and offer the best developer experience possible.
Our OpenAPI file would be generated by our new 'requests' spec folder. Here's a simple example:
# /spec/requests/api/workflows_spec.rb
RSpec.describe 'Workflows API', type: :request do
path '/api/v1/workflows' do
get("List workflows") do
tags "Workflows"
produces "application/json"
security [ bearer: [] ]
...
before do
...
end
response(200, "successful") do
...
run_test!
end
end
end
endWhat makes this approach powerful is what we can generate from these specs:
Every endpoint with consistent naming and structure
Input schema definitions (query params, request body) including examples, defaults, and required vs optional fields
Response schemas showing exactly what developers will receive back, with examples
Language-specific code examples for each SDK we offer
Consistent parameters across examples - this is subtle but crucial: all code examples use the same input parameters and return the same response
Tags and OperationIds for better SDK method naming and organization
Consistent summaries and descriptions - naming conventions across the board are extremely important for developer experience
2. Serializers with Rich Metadata
The API request responses and schemas needed to be pulled in automatically. Fortunately, we'd invested significant time in our API architecture and follow strict patterns, which made this portion manageable.
We use Blueprinter for serialization—every single API response already has a blueprint defined. For those unfamiliar, Blueprinter is a JSON serialization library that provides a simple, declarative way to define how your Ruby objects get converted to JSON. The plan was to enhance each field in every serializer with the necessary Swagger metadata. While Blueprinter doesn't have native support for Swagger, we designed a way to extract these attributes during our OpenAPI generation process.
class WorkflowBlueprint < BaseBlueprint
object :workflow
identifier :id
field :description,
swagger_type: :string,
swagger_nullable: true,
swagger_description: "Description of the workflow",
swagger_example: "Welcome workflow for new users"
end3. Properties and Params
We needed a way to define our query parameters and request body schemas. Many parameters are used across multiple endpoints—for example, all list endpoints share limit, starting_after, ending_before, and expand. DRYing up these common definitions was an easy win. A plain old Ruby object did the trick:
LIMIT_PARAM = {
name: :limit,
in: :query,
type: :integer,
required: false,
description: "Number of items to return (max 100)",
example: 25
}.freeze
...
And we can update our specs like so:
get("List workflows") do
...
parameter SwaggerSchemas::STARTING_AFTER_PARAM.dup
parameter SwaggerSchemas::ENDING_BEFORE_PARAM.dup
parameter SwaggerSchemas::LIMIT_PARAM.dup
parameter SwaggerSchemas::EXPAND_PARAM.dup
...
endWe followed the same pattern for properties and added simple procs for common properties that needed minor customizations based on the resource.
4. Code Samples
Deciding where code samples should live was perhaps the trickiest architectural decision. SDK repos? SDK code generator repo? Backend API?
Ultimately, it made the most sense to keep all code samples for all our SDKs defined in our Rails backend—one central place responsible for generating the OpenAPI file. A key benefit was that we could store the API request/response generated in the test, along with its schema from our serializer definitions, and use this exact response for all SDK examples. To ensure consistency, all inputs needed to be the same too. This approach eliminated coordination overhead between team members and reduced cross-system communication—everything lives in our API.
We created a Ruby module with predictable naming conventions:
RETRIEVE_USER = {
ruby: ->(path_params:, query_params:, body_params:, **) {
<<~RUBY.chomp
EmbedWorkflow::Users.fetch(key: "#{path_params[:key]}")
RUBY
},
typescript: ->(path_params:, query_params:, body_params:, **) {
<<~TS.chomp
const user = await embedWorkflow.users.fetch("#{path_params[:key]}");
TS
},
python: ->(path_params:, query_params:, body_params:, **) {
<<~PYTHON.chomp
user = embed_workflow.users.fetch("#{path_params[:key]}")
PYTHON
}
}Our constants follow the same naming convention as each endpoint's summary: get("Retrieve user"). This allows us to dynamically check if a constant exists in our generation script.
5. Response Schema Generation
Earlier I mentioned how we added metadata to our serializers. Now we needed to extract that metadata and inject it into our Swagger definitions.
The specs use our custom schema generator:
response(200, "successful") do
schema **SwaggerSchemas.response_schema(Api::WorkflowBlueprint)
...
end
We then wrote a custom method that generates an OpenAPI 3.0 valid schema:
def self.response_schema(blueprint, view = :default)
SwaggerSchemaGenerator.from_blueprint(blueprint, view: view).freeze
endThis method introspects the Blueprinter serializer and builds a proper OpenAPI schema complete with types, descriptions, examples, and nullable flags—all from the metadata we added to our serializers.
6. Bringing It All Together
With all these pieces in place, our CI pipeline runs a final generation script that:
1. Executes all RSwag tests to generate the base OpenAPI structure
2. Enhances each endpoint with our custom response schemas
3. Injects language-specific code examples for each operation
4. Validates the final OpenAPI spec against the 3.0 standard
5. Outputs a complete, accurate OpenAPI file ready for consumption
The real complexity wasn't in any individual piece—it was in designing a system where all these components work together seamlessly while remaining maintainable by our team.
The Results
After much refinement, here's what we achieved:
Zero documentation drift: Our docs are generated from our OpenAPI file. We wrote a custom script to generate endpoint pages in our home-grown doc site using Markdoc
Consistent SDK experience: All SDKs share identical method signatures and behaviors
Unlocked AI Possibilities: We are laying down a strong foundation for exciting AI projects that are underway
Reduced support burden: Clear, accurate docs with working examples dramatically reduced API-related support tickets
The Bigger Picture
This system serves three critical audiences that will define the future of API consumption:
Human developers get always-accurate documentation with examples that actually work
Our SDKs generate from a single source of truth, ensuring consistency across languages
AI agents can consume our OpenAPI spec to understand and use our API
That last point deserves emphasis. As more development happens through AI assistants, having a machine-readable, always-accurate API specification isn't just nice—it's essential. We're already seeing AI tools that can generate entire integrations from OpenAPI specs.
What this unlocks for AI: Our OpenAPI spec → TypeScript SDK → MCP (Model Context Protocol) server → AI agents that can actually use our API. We're already building an onboarding agent that can configure entire customer accounts through natural language. Imagine telling an AI "set up a welcome workflow for new users" and it actually does it—properly authenticated, with correct parameters, following your business logic. This is only possible because we have that reliable OpenAPI foundation.
By investing in this infrastructure now, we're future-proofing our platform.
Lessons Learned
If you're considering building something similar, here's what I wish I'd known at the start:
Start with the end in mind: Design your system thinking about all consumers (humans, SDKs, AI) from day one
Invest in conventions early: Consistent naming and patterns pay compound dividends
Make the right thing easy: If developers have to think about documentation, they won't do it
Test your examples: Nothing erodes trust faster than code examples that don't work
What's Next
This is just the foundation of our SDK generation system. In the upcoming posts, I'll dive into Part 2 on why we chose Markdoc over Docusaurus for our documentation site.
We're now building AI agents on top of this foundation—starting with natural language onboarding for new customers.
What's your approach to API documentation? Are you generating from tests, maintaining manually, or trying something completely different? I'd love to hear about your experiences—drop a comment or reach out on X.

Super interesting. Thanks for sharing and keep it going!